Samengestelde Tabel maken.
Vele enquêtes bevatten meerdere bij elkaar horende vragen met dezelfde antwoord categorieën. Zo is in de enquête gevraagd hoe belangrijk men de volgende aspecten vindt bij het kiezen van een gewenste nieuwe woonsituatie. De aspecten waren: Veiligheid van de buurt, Groene omgeving, Aanwezigheid balkon of tuin, Eigen parkeerplek, Openbaar vervoer op loopafstand, Centrum op loopafstand en HAN campus op loopafstand. Als antwoorden hebben al deze vragen: Zeer belangrijk, Belangrijk, Niet belangrijk maar ook niet onbelangrijk (neutraal), Onbelangrijk en Zeer onbelangrijk.
Omdat het nogal gecompliceerd en veel stappen omvat om dit zelf te doen maken we in eerste instantie gebruik van een package en wel het Package "tableone". Hoe je dit package kunt installeren, leer in je in "Install Packages". (Dit Package wordt ook gebruikt bij MR vragen).
Iets verder in deze paragraaf wordt uitgelegd hoe het ook zonder gebruik van een package kan, en hoe dan ook een samengesteld staafdiagram gemaakt kan worden.
M.b.v. het Package.
Installeer het Package "tableone" eenmalig en zorg iedere keer dat je het wilt gebruiken dat het geactiveerd is.
We maken als eerste een nieuwe variabele "SamenvatVar" aan waarin alle variabelen die we willen samenvatten.
> SamenvatVar=c("Omgeveilig","Omgegroen","Omgebalkon","Omgeparking","OmgeOV","OmgeCentr","OmgeHAN")
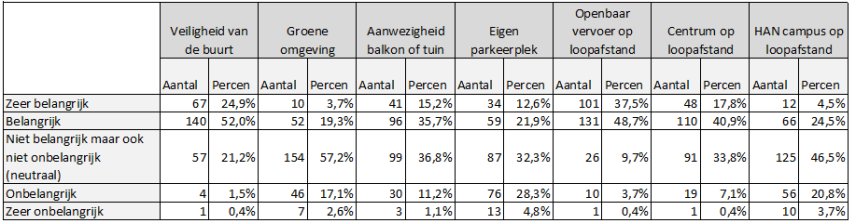
Van de variabele maken we een tabel met de naam TabelofFrequencies met de CreateTableOne Functie als volgt
> TabelOfFrequencies=CreateTableOne(vars = SamenvatVar,data = DataWoonwensenStudenten)
De datasetnaam moet je meegeven.
Laat je de inhoud zien van de nieuw aangemaakte variabele dan zie je het volgende:

Qua lay-out zou ik liever een meer compacte tabel hebben, voor mijn rapport. Helaas kan ik het niet op een makkelijke manier en R en maak ik zelf graag gebruik van Excel. Ik moet dan wel wat waarden overtypen, maar dan heb ik wel wat.
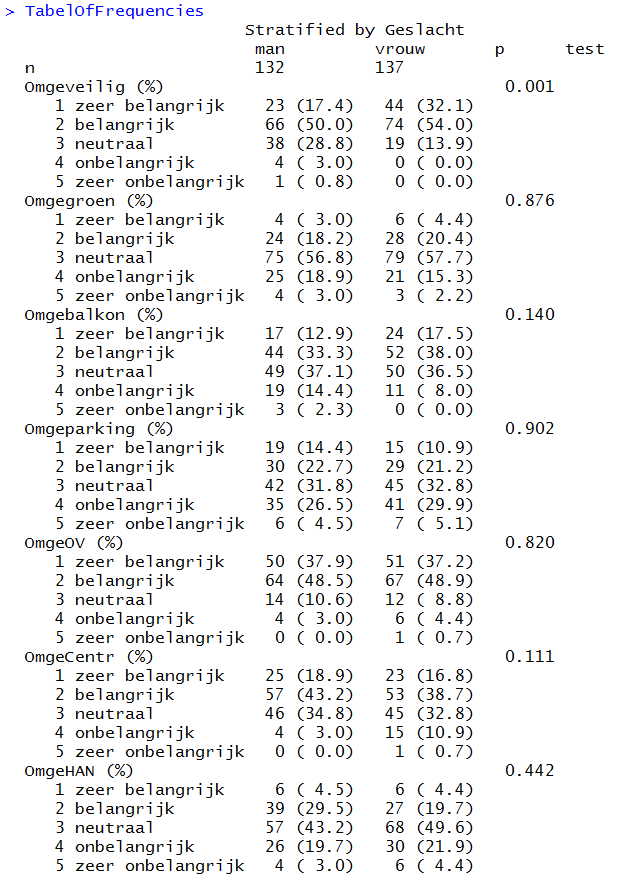
Wil je een vergelijking maken tussen mannen en vrouwen t.a.v. bovenstaande aspecten van belangrijkheid van wensen, dan kunnen we het CreateTableOne commando uitbreiden met:
strata = "Geslacht"
> TabelOfFrequencies=CreateTableOne(vars = SamenvatVar,strata = "Geslacht",data = DataWoonwensenStudenten)
Het resultaat hiervan is:
En weer voor de lay-out overzetten naar Excel, met alleen percentages, levert:
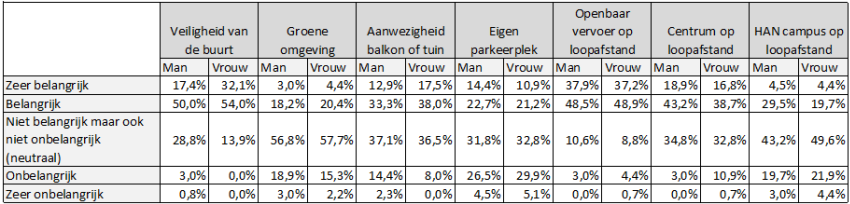
Als we zo de verschillen bekijken vinden de vrouwen de veiligheid en de aanwezigheid van een balkon of tuin net iets belangrijker, en de mannen de loopafstand tot centrum en campus.
Zonder gebruik te maken van een Package.
Wil je geen gebruik maken van een package dan is het van groot belang dat je snapt hoe tabellen in R opgebouwd worden. Stel we willen een vergelijkbare tabel maken als hierboven en gemakshalve willen we in de tabel alleen percentages weergeven. Met het commando
> perveilig=prop.table(table(Omgeveilig))
> perveilig
Omgeveilig
1 zeer belangrijk 2 belangrijk 3 neutraal 4 onbelangrijk 5 zeer onbelangrijk
0.249070632 0.520446097 0.211895911 0.014869888 0.003717472
worden de percentages van Omgeveilig weergegeven. Dit doen we ook voor de andere bijbehorende variabelen.
> pergroen=prop.table(table(Omgegroen))
> perbalkon=prop.table(table(Omgebalkon))
> perparking=prop.table(table(Omgeparking))
> perov=prop.table(table(OmgeOV))
> percentrum=prop.table(table(OmgeCentr))
> perhan=prop.table(table(OmgeHAN))
Met het matrix commando kunnen we deze waarde combineren tot een lange rij waarden.
> matrix(c(perveilig,pergroen,perbalkon,perparking,perov,percentrum,perhan))

Merk op dat de eerste 5 getallen de 5 waarden voor perveilig zijn, de volgende 5 voor pergroen enz. Als we nu de matrix op 5 rijen instellen met de "nrow" functie krijgen we de volgende indeling:
> matrix(c(perveilig,pergroen,perbalkon,perparking,perov,percentrum,perhan),nrow = 5)

Nu is iedere kolom een variabele.
De rijlabels zijn de waarden behorende bij de variabelen
> labelsrijen=names(perveilig)
> labelsrijen
[1] "1 zeer belangrijk" "2 belangrijk" "3 neutraal" "4 onbelangrijk" "5 zeer onbelangrijk"
De labels van de kolommen zijn de variabelen, alleen zijn deze namen niet begrijpelijk. Daarom definiëren we ze als volgt:
> labelskolommen=c("Veiligheid buurt","Groene omgeving", "Balkon of tuin","Eigen parkeerplek","Openb. vervoer loopafstand","Centrum loopafstand","HAN campus loopafstand" )
> labelskolommen
[1] "Veiligheid buurt" "Groene omgeving" "Balkon of tuin" "Eigen parkeerplek" [5] "Openb. vervoer loopafstand" "Centrum loopafstand" "HAN campus loopafstand"
In de matrix kunnen we met de rij- en kolomlabels toevoegen met de functie:
dimnames = list(labelsrijen,labelskolommen)
De matrix wordt dan:
> matrix(c(perveilig,pergroen,perbalkon,perparking,perov,percentrum,perhan),nrow = 5,dimnames = list(labelsrijen,labelskolommen))

In de tabel willen we percentages aangeven, dat wil zeggen dat we het geheel met 100 kunnen vermenigvuldigen. En we kennen aan de uitkomst een nieuwe variabelenaam "Tabeloffrquencies" toe zodat deze ook makkelijk in het barplot is in te vullen.
> Tabeloffrequencies=matrix(c(perveilig,pergroen,perbalkon,perparking,perov,percentrum,perhan),nrow = 5,dimnames = list(labelsrijen,labelskolommen))*100
> Tabeloffrequencies

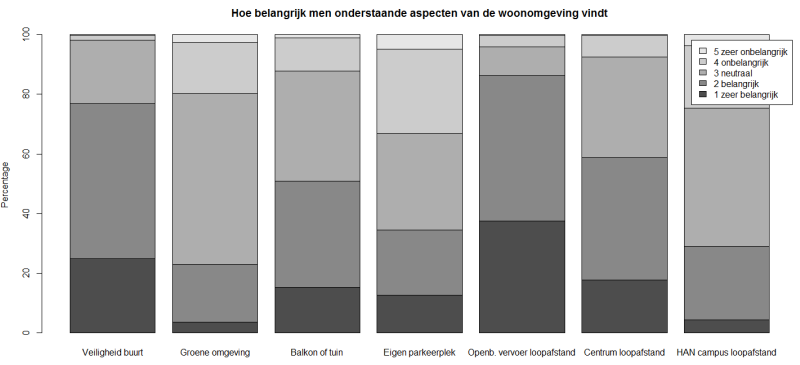
Van deze Tabeloffrequencies maken we een barplot
> barplot(Tabeloffrequencies)
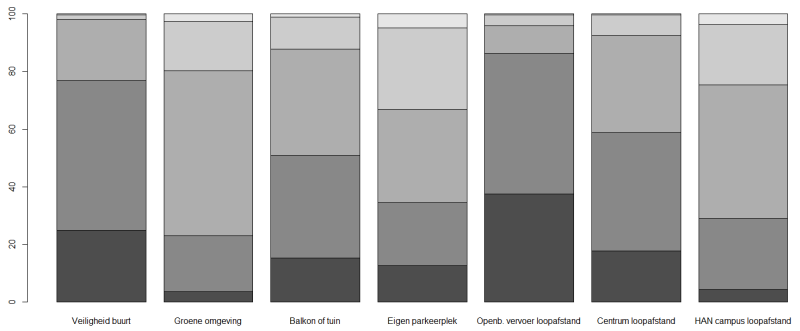
Het kan zijn dat je het schermdeel waarin de grafiek komt veel groter moet trekken om de volledige grafiek met alle kolomnamen te zien.
De laatste stap is de grafiek voorzien van namen en legenda:
main = "Hoe belangrijk men onderstaande aspecten van de woonomgeving vindt" (titel grafiek)
ylab = "Percentage" (Titel Y-as)
legend.text = rownames(perbalkon) (Legenda)
Dit geeft:
> barplot(Tabeloffrequencies,main = "Hoe belangrijk men onderstaande aspecten van de woonomgeving vindt" ,ylab = "Percentage",legend.text = rownames(perbalkon))