Uitleg werking script descriptives voor het berekenen van aantal, minimum, maximum, gemiddelde, standaardeviatie, standaardschattingsfout en 95% betrouwbaarheid interval.
Het volledige script ziet er als volgt uit:

De regels die beginnen met een # geven uitleg, en worden nooit als commando uitgevoerd.
In Regel
7 wordt een nieuwe variabele gedefinieerd met de naam "Variabele". Deze krijgt de naam van de variabele waarop je de verschillende berekeningen wilt uitvoeren.
In de regels 11 t/m 14 worden respectievelijk het Minimum, het Maximum, het Gemiddelde en de standaardeviatie berekend van "variabele", maar dat is door regel 7 de variabele uit de dataset geworden.
De gebruikte functies hebben het nadeel dat als er missing values in de dataset staan, de berekeningen niet uitgevoerd worden. Door "na.rm = TRUE"
toe te voegen (not available. remove), worden de velden waarin NA staat niet meegenomen. (Bedenk dat R hoofdletter gevoelig is, dus waar je i.p.v. een kleine letter een hoofdletter of andersom invoert, zal het commando niet uitgevoerd worden).
De standaardschattingsfout wordt als volgt uitgerekend bij een scale variabele.
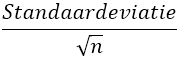
Hierbij is n het aantal geldige waarnemingen. In de dataset DataWoonwensenStudenten zijn 269 waarnemingen gedaan, te berekenen door:
> length(WoLastwens)
[1] 269
19 verschillende respondenten hebben niets ingevuld wat we als volgt kunnen zien:
> summary(WoLastwens)
![]()
De n in de formule is dus 269 -19 is 250.
helaas ken ik niet een directe functie om automatisch het aantal wel in gevulde waarden uit te laten rekenen.
Getrukeerd kan het wel en wel als volgt:
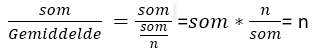
Delen we de som van de waarden door het gemiddelde. Het gemiddelde is de som gedeeld door n. Delen door een breuk is hetzelfde als vermenigvuldigen met het omgekeerde.
dan kunnen we som boven de streep wegstrepen tegen som onder de streep en houden we n over. In R
> Aantalwaarden=sum(WoLastwens,na.rm = TRUE)/mean(WoLastwens,na.rm = TRUE)
> Aantalwaarden
[1] 250
In het script is dit regel 20.
De standaardschattingsfout is en in R als volgt te berekenen:
> StandaardSchattingsFout=sd(WoLastwens,na.rm = TRUE)/sqrt(Aantalwaarden)
> StandaardSchattingsFout
[1] 10.62642
Vervolgens worden de ondergrens en de bovengrens berekend.
> Ondergrens=mean(WoLastwens,na.rm = TRUE)-2*StandaardSchattingsFout
> Bovengrens=mean(WoLastwens,na.rm = TRUE)+2*StandaardSchattingsFout
Wil je het 99% betrouwbaarheid interval vul dan i.p.v. 2 de waarde 3 in.
Vervolgens worden de waarden bij elkaar verzameld, de labels van de rijen, en het geheel wordt in een matrix geplaatst.
> Waarden=c(Aantalwaarden,Minimum,Maximum,Gemiddelde, standaarddeviatie,StandaardSchattingsFout,Ondergrens,Bovengrens)
> Lbabelsrij=c("Aantal","Minimum", "Maximum","Gemiddelde", "Std.Deviatie","Standaardschattingsfout", "Ondergrens","Bovengrens")
> matrix(Waarden,dimnames= list(Lbabelsrij,"Waarden"))
