Lineaire regressie.
Wil je naar verbanden kijken tussen twee scale variabelen dan maak je gebruik van de lineaire regressie techniek. Verbanden tussen twee scale variabelen worden weergegeven door de correlatie coëfficiënt R. R is een waarde tussen +1 en -1. Naarmate R dichter bij de +1 ligt is er sprake van een positief verband, naarmate de R dichter bij de -1 ligt, een negatief verband en naarmate de R dicht bij 0 ligt geen verband.
Laten we kijken of er een verband is tussen de leeftijd en het inkomen. R berekenen we met de functie cor(x,y), waarbij x de onafhankelijke variabele is en y de afhankelijke. Bij leeftijd en inkomen is leeftijd de onafhankelijke die het inkomen (de afhankelijke) bepaalt.
> cor(Leeftijd,Inkomen)
[1] 0.4850048
R is hier 0.49, dat is niet erg veel. De andere scale variabelen in dit bestand blijken nog minder verband met elkaar te hebben, dus in eerste instantie gaan we voor de technieken verder met leeftijd en inkomen.
Visueel wordt het verband vaak aangetoond met een spreidingsdiagram. Het hierbij behorende spreidingsdiagram is:
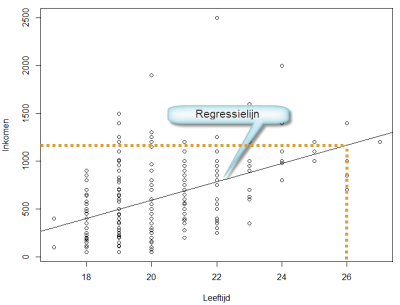 |
Hoe je dit spreidingsdiagram kunt maken wordt uitgelegd in het onderdeel spreidingsdiagram. |
Is het verband erg groot, dan liggen de punten ongeveer op een lijn, is het verband niet groot, dan liggen de punten verder van de lijn. Die lijn heet de regressielijn en wordt gebruikt om te voorspellen. Zo zou iemand van 26 (X-as 26 jaar) grofweg 1200 aan inkomen hebben (Zie stippellijnen in grafiek).
De vergelijking van de regressielijn kun je berekenen. Daarvoor maak je een lineair regressiemodel met de LM functie.
![]()
waarbij y de afhankelijke variabele is, en x de onafhankelijke. Omdat je een regressiemodel vaker gebruikt, maken we er een variabele van met een logische naam b.v.:
> LinRegModel=lm(Inkomen~Leeftijd)
Een summary van het LinRegModel levert het volgende op:
> summary(LinRegModel)
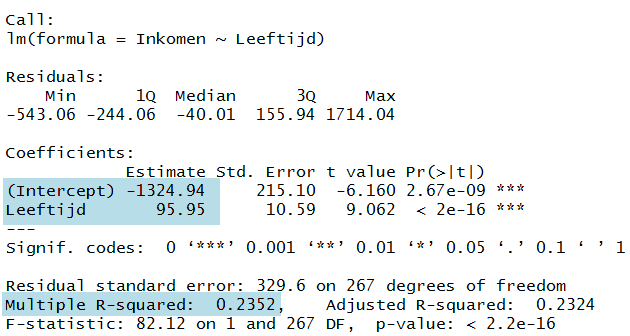
Hierbij zijn de gearceerde waarden voor ons van belang.
Ten eerste de R-Squared.
Dit is het kwadraat van de R waarde (ga na).
Met R-squared kun je aangeven dat het inkomen voor 23% verklaard wordt door de leeftijd. Er zijn dus naast de leeftijd meerdere andere factoren die het inkomen verklaren.
De andere twee factoren die van belang zijn, zijn de Intercept en leeftijd. Uit de wiskunde weet je nog dat de vergelijking van een lijn is: Y = a X + b. (a is de richtingscoëfficiënt, b snijpunt met de Y-as).
Passen je dat hier toe, dan is a=95,95 en b=-1324,94 ofwel we krijgen de vergelijking:
Inkomen = 95,95*Leeftijd - 1324,94
Vullen je in de vergelijking 26 voor de leeftijd in, dan is de voorspelling van het inkomen 1169,76.
Je kunt je voorstellen dat er een verschillen is in het verband tussen leeftijd en inkomen voor mannen en vrouwen. Willen we alleen b.v. de leeftijden van de mannen bekijken, dan kan dat als volgt:
> Leeftijd[Geslacht=="man"]

R gebruikt voor het gelijk teken de dubbele == (enkele is om een waarde toe te wijzen aan een variabele). Door dit tussen rechte haken achter leeftijd te plaatsen krijg ik alleen de leeftijden van de mannen. Dit kan ik ook met het inkomen doen, en samen levert dat op:
> cor(Leeftijd[Geslacht=="man"],Inkomen[Geslacht=="man"])
[1] 0.5205038
en voor de vrouwen:
> cor(Leeftijd[Geslacht=="vrouw"],Inkomen[Geslacht=="vrouw"])
[1] 0.4282519
Bij de mannen wordt het inkomen dus net iets meer verklaard door de leeftijd, maar erg groot is het verband niet.