Verkenning dataset.
Indien je een nieuw bestand of dataset geladen hebt is het verstandig om eerst deze dataset goed te bekijken voordat je gaat analyseren. De functie "dim" (bedenk dat R hoofdletter gevoelig is) geeft aan om hoeveel data en variabelen het gaat.
> dim(DataWoonwensenStudenten)
[1] 269 35
Er zijn 269 waarnemingen geweest waarbij bij iedere waarneming 35 variabelen zijn gemeten.
De functie "str" geeft inzicht in het meetniveau van variabelen.
> str(DataWoonwensenStudenten)
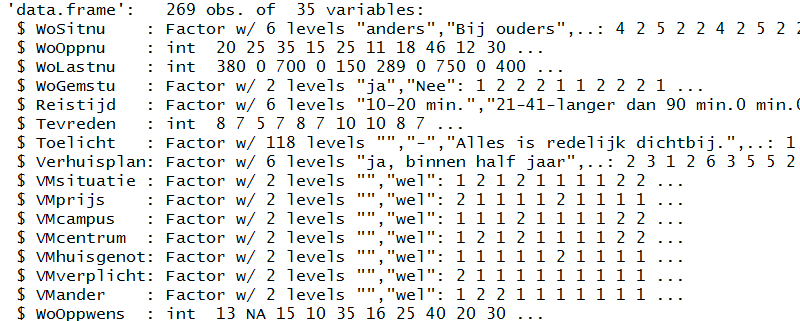
Van de variabele WoSitnu (woonsituatie nu) wordt aangegeven dat het een categoriale variabele (Factor) is met 6 verschillende waarden, waarbij "anders" de waarde 4 heeft en "bij ouders" de waarde 2.
Het meetniveau van WoOppnu (woonoppervlakte nu) is Ratio (int van integer).
De functie "str" kan op ieder R object gebruikt worden, dus ook op een variabele, en wel als volgt:
> str(Omgeveilig)
![]()
De variabele Omgeveilig (meet de belangrijkheid van het aspect veiligheid in de buurt) is een categoriale variabele. Categoriale variabelen kunnen nominaal of ordinaal zijn. Omgeveilig is een ordinale variabele, dus speelt de volgorde (ordening) een rol.
N.a.v. het bekijken van de structuur heb ik de namen veranderd van:
"belangrijk", "neutraal", "onbelangrijk", "zeer belangrijk", "zeer onbelangrijk"
in
"1 zeer belangrijk", "2 belangrijk", "3 neutraal", "4 onbelangrijk", "5 zeer onbelangrijk"
Deze verandering heb ik gedaan met de zoek en vervang functie in het Excel bestand.
De volgorde bepaald straks ook de volgorde waarin de waarden in tabellen of grafieken komen te staan, en is van essentieel belang. Een berekening van de mediaan zal in het eerste geval misschien een andere mediaan geven dan in het tweede geval.
Wil ik alleen de namen zien van de variabelen dan gebruik ik de functie "names".
> names(DataWoonwensenStudenten)

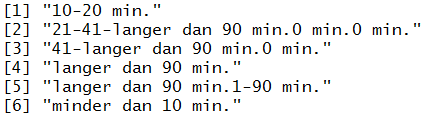
Wil ik de waarden zien van de variabele dan gebruik ik "levels".
> levels(Reistijd)
Een andere functie die al iets meer info geeft over de data is de "summary" functie.
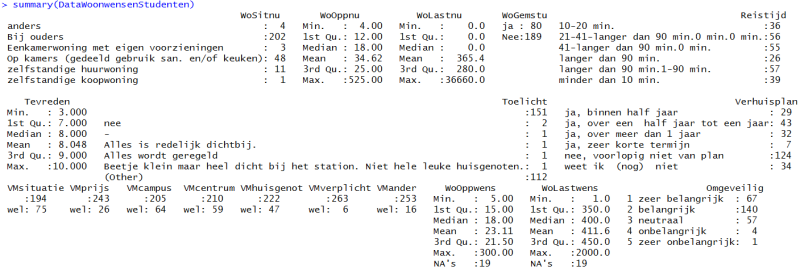
Je ziet dat voor alle variabelen summarys worden berekend. R houdt rekening met het meetniveau. Voor nominale en ordinale variabelen worden frequentietabellen gemaakt, voor interval of ratio variabelen worden Min, Max, kwartielen en gemiddelde berekend.
De summary functie is overigens ook gewoon te gebruiken voor een variabele b.v.
> summary(Leeftijd)
![]()
Nadat je bovenstaande functies toegepast hebt op je dataset, eventueel je dataset enigzins aangepast (b.v. zoals gedaan bij de ordinale variabele) hebt, kun je met de echte analyses beginnen.