Independent sample T-test.
Om te toetsen of er verschil is in de uitkomsten van waarden van twee variabelen waarvan de ene een kwalitatief meetniveau (nominaal of ordinaal) en de andere een kwantitatief meetniveau (scale) wordt de independent sample T-test gebruikt. Daarnaast kan de t-test alleen toegepast worden op een kwalitatieve variabele met maar twee waarden, of een kwalitatieve variabele waarvan het aantal waarden is terug gebracht tot 2. Zie voorbeeld 2.
Voorbeeld 1.
Stel we willen weten of er verschil is in woonlasten tussen mannen en vrouwen. Om hier snel inzicht in te krijgen kunnen we een boxplot maken.
> boxplot(WoLastnu~Geslacht)
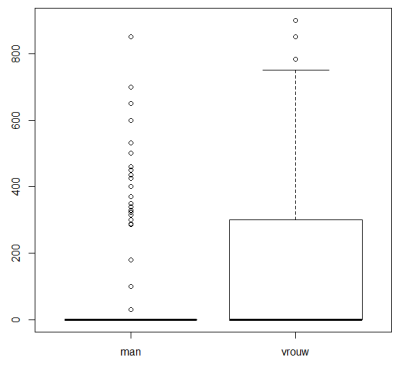
Zo te zien is er een verschil. Bij beiden heeft 50% (mediaan) woonlasten van 0, boven de 0 zijn er bij de mannen maar enkelen (uitzonderingen worden weergegeven met een "°", en bij de vrouwen is het meer regel dan uitzondering (blok van mediaan tot 3e kwartiel kan getekend worden). We zouden het gemiddelde kunnen uit laten rekenen, maar in t-test wordt dit ook gedaan.
Het commando om de t-test uit te voeren is t.test(scale var ~ Kwal. Var), hier toegepast:
> t.test(WoLastnu~Geslacht)

We zien dat de gemiddelde woonlasten voor vrouwen veel hoger ligt. De vraag is, of dit significant is. Daarvoor kijken we naar de p-waarde. Die is 6,5% (0.06452). Dit is boven de 5%, dus er is geen significant verschil in woonlasten tussen mannen en vrouwen.
We hebben hier tweezijdig getoetst, wat als we eenzijdig zouden toetsen. De alternatieve Hypothese zou dan zijn dat mannen minder woonlasten hebben dan vrouwen. Eenzijdig toetsen doen we als volgt:
> t.test(WoLastnu~Geslacht,alternative="less")

Door het t-test() commando uit te breiden met "alternative = "less" toetsen we eenzijdig. Dan is
H0 : De gemiddelde
woonlasten van mannen zijn hoger of gelijk aan die van vrouwen.
H1 : De gemiddelde
woonlasten van mannen zijn lager dan die van vrouwen.
Eenzijdig is er nu wel een significant verschil.
Misschien is het niet helemaal eerlijk om alle woonlasten inclusief 0 mee te nemen. We kunnen ons ook beperken tot die personen die wel woonlasten hebben. In het boxplot doe je dat als volgt:
> boxplot(WoLastnu[WoLastnu>0]~Geslacht[WoLastnu>0])
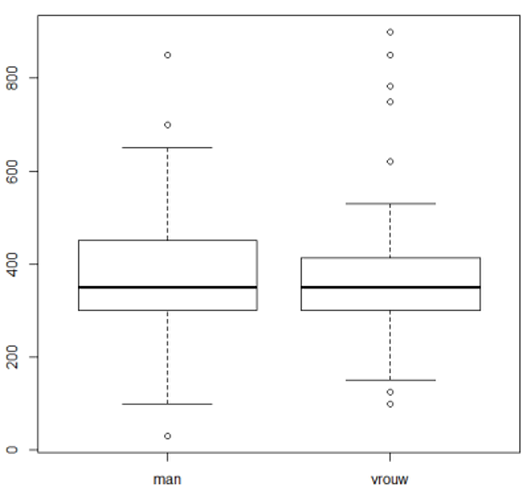
Uitleg: Indien je een variabele naam uitbreidt met rechte haken, zal datgene wat tussen de rechte haken staat als voorwaarde gelden. Dus WoLastnu[Wolastnu>0] en Geslacht[WoLastnu>0] geven alleen die personen waarvan de woonlasten groter dan 0 zijn.

In de boxplot is te zien dat er nauwelijks verschil is tussen mannen en vrouwen, en uit de t-test komt het volgende:
> t.test(WoLastnu[WoLastnu>0]~Geslacht[WoLastnu>0])

Het verschil is uiterst klein en de kans dat dit voorkomt is 77%.
Voorbeeld 2.
Stel we willen kijken of er een verband is tussen de woonsituatie en de leeftijd. We onderzoeken kort wat er aan de hand kan zijn, ten eerste door een boxplot toe te passen.
> boxplot(Leeftijd~WoSitnu,las=2)
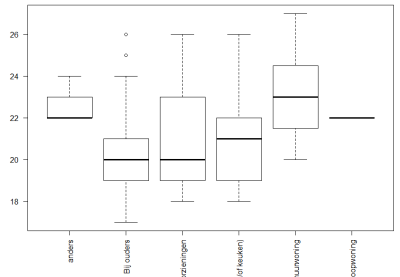
Er zijn duidelijk verschillen te zien, maar voor de t-toets mag ik maar twee waarden gebruiken. De aantallen spelen ook een rol. In groepsvergelijking staat hoe met het describeby() commando (in package (psych) ) we inzicht krijgen in de verschillende waarden zoals het gemiddelde.
> describeBy(Leeftijd,WoSitnu,mat = TRUE)

Kijk ik naar de aantallen en naar de gemiddelde leeftijden, dan zou ik willen testen of er verschil in leeftijden zit tussen de mensen die bij hun ouder wonen en die op kamers wonen.
Dit kan ik als volgt testen met de t-test:
> t.test(WoLastwens[WoSitnu=="Bij ouders"],WoLastnu[WoSitnu=="Op kamers (gedeeld gebruik san. en/of keuken)"])
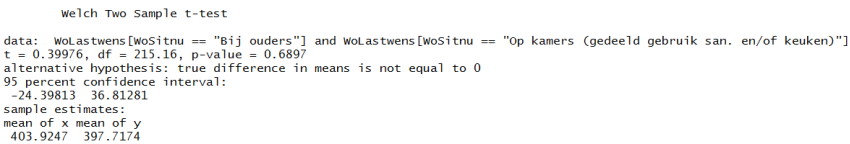
Uitleg: Ik test de groep die bij de ouders woont WoSitnu=="Bij ouders" tegen de groep die op kamers woont WoSitnu== "Op kamers (gedeeld gebruik san. en/of keuken)"].
Let op er staat een dubbel = teken "==". Enkel wil zeggen in R toewijzen.
Tussen de twee groepen staat niet een "~" teken maar een komma.
Als we naar voorbeeld 1 kijken dan is:
Gelijk aan:
> t.test(WoLastnu[Geslacht=="man"],WoLastnu[Geslacht=="vrouw"])

Ga maar na.