Descriptives voor scale variabelen.
Om inzicht te krijgen in de verdeling van een scale variabele worden verschillende technieken gebruikt. Standaard heeft R geen functie waarin al deze technieken tegelijk vertegenwoordigd zijn. Er zijn packages waarin wel veel aanwezig is, maar net niet alles wat we willen hebben. Vandaar dat we een eigen script gaan gebruiken.
Ook de lay-out van de analyses vind ik niet erg mooi. Vandaar dat ik zelf vaker de berekende waarden kopieer en plak naar Excel om daar een mooie tabel van de verzamelde scale variabelen te maken.
R heeft de volgende functies:
De Summary Functie geeft de standaard waarden voor een scale variabele. Bijvoorbeeld
> summary(Leeftijd)
![]()
Naast min, max kwartielen, mediaan en gemiddelde willen we ook graag de standaardeviatie, de standaardschattingsfout en het betrouwbaarheidsinterval weten.
Voor de standaarddeviatie heeft R de functie:
> sd(Leeftijd)
[1] 1.901656
Willen we de standaarddeviatie (of gemiddelde of een andere statistische functie) van de WoLastwens bereken dan is het resultaat:
> sd(WoLastwens)
[1] NA
NA (Not Available) wil zeggen dat er waarden niet ingevoerd zijn (missing values). In de dataset zie je dit als volgt:
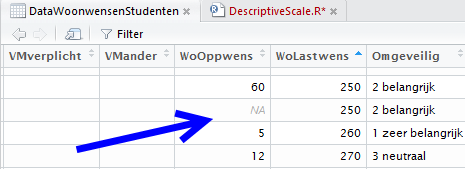
Indien je de sd functie uitbreidt met
[1] 168.0185
worden de Not Available verwijderd (Remove).
Idem
> mean(WoLastwens,na.rm = TRUE)
[1] 411.62
Om steeds opnieuw de commando's in te toetsen is veel werk. Daarom heb ik een script (klein programmaatje) gemaakt hoe dit in een keer te doen. Dit script kun je hier downloaden via de link DescriptiveScale.R Script.
Wil je de achtergrond weten van de werking van dit script, bekijk dan "Uitleg script DescriptiveScale.R".
Open het script bestand. (Hoe script bestand openen)
Toepassen van het script bestand voor het berekenen van waarden scale variabele
Indien je het script bestand geopend hebt, zie je het volgende scherm:
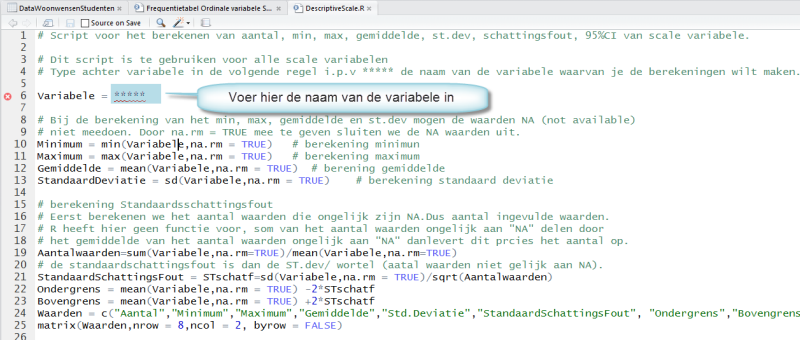
Vul op de plaats waar de ***** staan de naam van de variabele in, b.v. WoGemstu. Selecteer dan alle regels in het script venster door de toetsen combinatie "CTRL A".
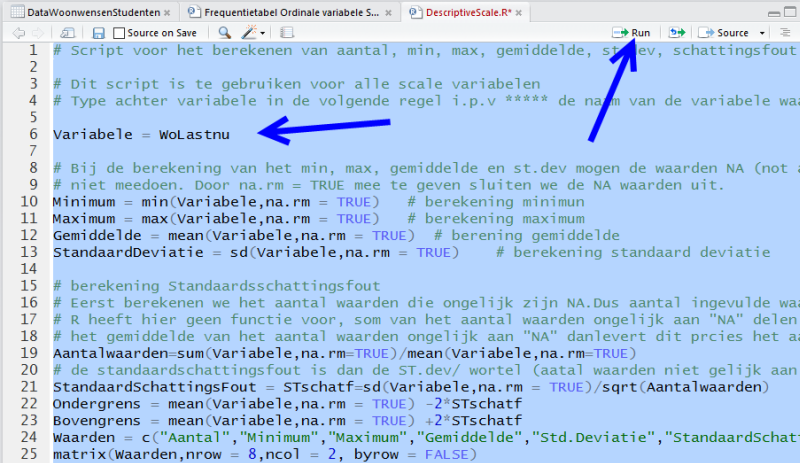
Klik dan op Run of CTRL Enter om het script uit te voeren. Het resultaat is:
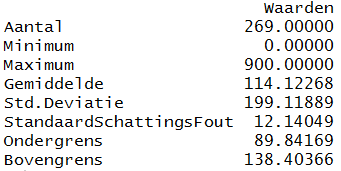
Deze waarden kopieer ik vervolgens zelf naar Excel met al de andere scale variabelen zodat ik de volgende tabel krijg:

Probeer ook zo'n Excel schema te maken voor alle scale variabelen.
Zie Groepsvergelijkingen hoe je het op een nog andere manier kunt doen.