Pearson PM toets.
De Pearson PM toets wordt gebruikt om te toetsen of de geconstateerde samenhang tussen twee scale variabelen wel of niet van het toeval afhangt. Om te kijken of er en hoe groot de verbanden zijn tussen twee variabelen gebruiken we Lineaire Regressie. Voor uitleg van de hieronder gebruikte commando's zie daarvoor het onderdeel Lineaire Regressie. In dat onderdeel hebben we al gezien dat in de gebruikte dataset weinig sprake is van echt verband. De variabelen waartussen het meeste verband was waren leeftijd en inkomen, ook al was dit verband niet groot. In voorbeeld 1 zullen we de Pearson PM toets voor het verband tussen leeftijd en inkomen bespreken, voor voorbeeld 2 nemen we een voorbeeld waar wel veel verband tussen zit, maar waarvan de data niet in de gebruikte dataset zit.
Voorbeeld 1
We bekijken het verband tussen Leeftijd (onafhankelijke, x) en inkomen (afhankelijke, Y).
De correlatiecoëfficiënt R is:
> cor(Leeftijd,Inkomen)
[1] 0.4850048
Het spreidingsdiagram is
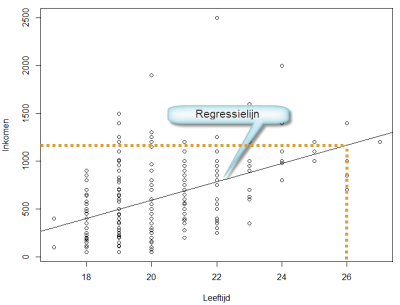
Uit beiden zien we al dat het verband niet erg groot is.
Standaard R heeft geen functie om te toetsen of het gevonden verband, hoe klein ook op toeval berust. Willen we dat toch weten dan moeten we een extra package "Hmisc" installeren. Hoe je een package installeert zie je in "Installeren Package".
Installeer het package " Hmisc ".
Om de Pearson moment toets uit te voeren geef het commando:
> rcorr(Leeftijd,Inkomen,type="pearson")
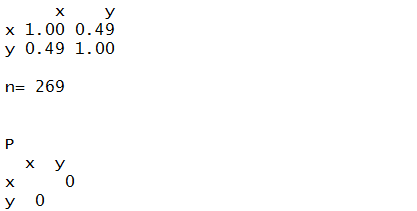
In  staat de x voor leeftijd een de y voor inkomen.
staat de x voor leeftijd een de y voor inkomen.
Het kruispunt tussen X en X is de correlatiecoëfficiënt tussen X en X. De correlatiecoëfficiënt tussen een variabele en zichzelf is altijd 1.
Daarnaast staat de correlatiecoëfficiënt tussen x en y, en die is 0,49. Dit hadden we al eerder gezien met het "cor()" commando.
D e tweede matrix  geeft de significantieniveaus aan. Afgerond want eigenlijk staat er een heel erg klein getal (2,8108E-17). Dit getal is kleiner dan 5%, dus mogen we aannemen dat het verband niet op toeval berust. Bedenk wel dat er nauwelijks verband is.
geeft de significantieniveaus aan. Afgerond want eigenlijk staat er een heel erg klein getal (2,8108E-17). Dit getal is kleiner dan 5%, dus mogen we aannemen dat het verband niet op toeval berust. Bedenk wel dat er nauwelijks verband is.
Zouden we kijken met de rcorr() functie naar het verband tussen woonoppervlakte en woonlasten
> rcorr(WoOppnu,WoLastnu,type = "pearson")
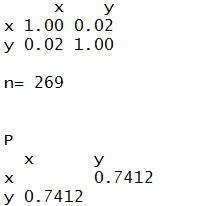
dan zien we dat de correlatiecoëfficiënt 0,02 is (heel erg klein) maar ook dat het significantieniveau 74% is. M.a.w. verband is er niet, en ook niet significant.
Voorbeeld 2
Voor dit voorbeeld gebruiken we het volgende bestand "VerkopenAantalVerkopers.csv". Download dit bestand en roep het op in R.
Om inzicht te krijgen in de relatie tussen het aantal verkopers (Onafhankelijke, x) en de verkopen (afhankelijke, y) voeren we de volgende
commando's uit in R.
> cor(AantalVerkopers,VerkoopInMiljoenen)
[1] 0.7765711
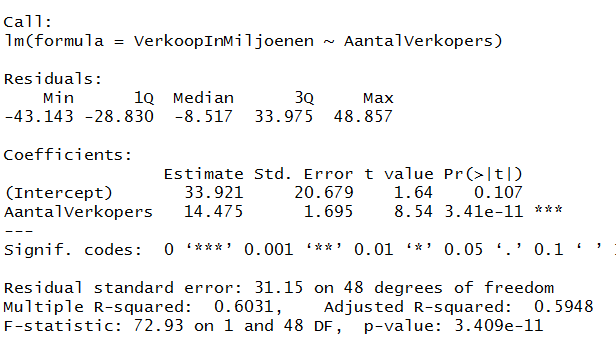
> LinRegModel=lm(VerkoopInMiljoenen~AantalVerkopers)
> summary(LinRegModel)
> rcorr(AantalVerkopers,VerkoopInMiljoenen)
x y
x 1.00 0.78
y 0.78 1.00
n= 50
P
x y
x 0
y 0
Uit de cor functie maar ook uit matrix onder rcorr zien we dat er een redelijk verband is n.l. 0,78.
Uit de R-square zien we dat het aantal verkopen voor 60,3% verklaard wordt door het aantal verkopers.
Uit de tweede matrix onder rcorr halen we
dat dat verband significant is (er staat de waarde 0, dit is afgerond, maar zeker kleiner dan 5%).
Er is dus een significant verband tussen het aantal verkopers en het aantal verkopen.